library(spuriouscorrelations)
nic_cage <- spurious_correlations[spurious_correlations$var2_short == "Nicholas Cage", ]
cor(nic_cage$var1_value, nic_cage$var2_value)[1] 0.6660043Puedes enviarme preguntas para el blog utilizando este formulario y suscribirse para recibir un correo electrónico cuando haya una nueva publicación.
En el siguiente botón puedes donar de forma voluntaria para apoyar mis proyectos de código abierto:

https://www.linkedin.com/posts/david-hernandez-59922a2b5_rstudio-economia-sociedad-activity-7407837205282566144-pXdg?utm_source=share&utm_medium=member_desktop&rcm=ACoAACapm70B8gb_KOUC8zVHWyNfd4tr4zWKpiU
Me encontré con un post de David Hernández que afirma lo siguiente:
Siguiendo mis estudios del efecto del libre mercado en la sociedad, ahora me encuentro que la corrupción y la libertad son inversamente proporcionales… Hice el análisis en Rstudio y tiene un coeficiente -0,74, a medida que aumenta la corrupción disminuye la libertad económica (y viceversa) Tiene sentido, incluso sin los datos, la corrupción solo puede existir con un poder centralizado (como el estado), en cambio, dónde todo el mundo es dueño de su vida, donde es tu propio dinero el que está en juego, no hay incentivo para ser corrupto.
El post incluye el siguiente gráfico: 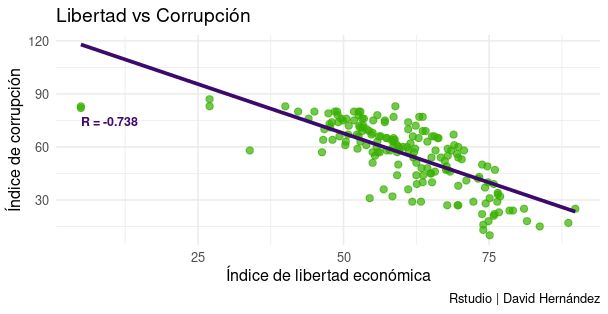
Analicemos críticamente este post.
Primero, el gráfico muestra una correlación negativa entre dos variables: corrupción y libertad económica. Sin embargo, correlación no implica causalidad. El hecho de que estas dos variables estén relacionadas no significa que una cause la otra.
Ya me referí a esto en un post anterior sobre correlación espuria, donde expliqué que dos variables pueden tener una alta correlación sin que exista una relación causal directa entre ellas. Vuelvo al ejemplo de “cantidad de películas de Nicholas Cage” y “cantidad de ahogamientos en piscinas”:
library(spuriouscorrelations)
nic_cage <- spurious_correlations[spurious_correlations$var2_short == "Nicholas Cage", ]
cor(nic_cage$var1_value, nic_cage$var2_value)[1] 0.6660043Si extendemos el análisis un poco, la regresión lineal entre ambas variables muestra lo siguiente:
lm_cage <- lm(var1_value ~ var2_value, data = nic_cage)
summary(lm_cage)
Call:
lm(formula = var1_value ~ var2_value, data = nic_cage)
Residuals:
Min 1Q Median 3Q Max
-8.418 -6.597 1.045 3.224 12.582
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 87.134 5.443 16.009 6.4e-08 ***
var2_value 5.821 2.173 2.678 0.0253 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.585 on 9 degrees of freedom
Multiple R-squared: 0.4436, Adjusted R-squared: 0.3817
F-statistic: 7.174 on 1 and 9 DF, p-value: 0.02527Según esto, la pendiente de la regresión es estadísticamente significativa, es decir que es estadísticamente distinta de cero. Pero esto no significa que ver más películas de Nicholas Cage cause más ahogamientos en piscinas, o viceversa más allá de que el modelo nos dice que cada película adicional de Nicholas Cage conduce a cinco ahogamientos adicionales en piscinas. Simplemente es una coincidencia estadística.
Volviendo al post de David Hernández, la afirmación de que “la corrupción y la libertad son inversamente proporcionales” debe ser analizada. No quiero caer en las tonterías de LinkedIn de poner “haha” o comentar groserías, al fin y al cabo más allá de mi título de ingeniero he dictado tutoriales y clases en varias universidades por muchos años en castellano e inglés.
Partamos por la definición de libertad. El gráfico se refiere a libertad económica, que es una dimensión específica de la libertad que se centra en la capacidad de los individuos para tomar decisiones económicas sin interferencia del gobierno. Esto no necesariamente se traduce en libertad política o social. Si vamos a la definición de F. A. Hayek la libertad se define de forma negativa como la ausencia de coerción arbitraria y no como la mera ausencia de regulación económica.
Es más, Hayek hace hincapié en que preservar la libertad individual es condición necesaria para la eficiencia económica, pero no suficiente. La libertad económica sin un marco legal que proteja los derechos civiles, políticos y de propiedad puede llevar a la erosión de la libertad por medio de la concentración de poder económico y político.
Por otro lado, la corrupción es un fenómeno complejo que puede tener múltiples causas y manifestaciones. La afirmación de que “la corrupción solo puede existir con un poder centralizado (como el estado)” es una simplificación excesiva. La corrupción puede ocurrir en diversos contextos, incluyendo tanto en estados con alta intervención económica como en aquellos con economías más libres. D. Sanjurjo analiza cómo la concentración económica y los vacíos institucionales en democrácias débiles pueden fomentar la corrupción, independientemente del grado de libertad económica por medio del clientelismo.
En lo que sigue, me referiré a la regresión lineal que se muestra en el gráfico original. Obtuve los datos del año 2024 de percepción de corrupción proporcionados por Transparencia Internacional y libertad económica proporcionados por Heritage Foundation para reproducir el análisis:
library(readr)
library(dplyr)
library(janitor)
libertad <- read_csv("heritage-index-of-economic-freedom-20251221191817.csv", skip = 4) %>%
clean_names()
glimpse(libertad)Rows: 184
Columns: 15
$ country <chr> "Afghanistan", "Albania", "Algeria", "Angola", …
$ index_year <dbl> 2024, 2024, 2024, 2024, 2024, 2024, 2024, 2024,…
$ overall_score <chr> "N/A", "64.8", "43.9", "54.3", "49.9", "64.9", …
$ property_rights <chr> "4.9", "56.8", "27.5", "40.4", "34.5", "50.3", …
$ government_integrity <chr> "18.1", "36.6", "27.7", "27.8", "39.8", "50", "…
$ judicial_effectiveness <chr> "4.9", "50", "28.9", "25.7", "55.8", "31.6", "9…
$ tax_burden <chr> "N/A", "88.8", "79.4", "86.5", "67", "87.6", "6…
$ government_spending <chr> "N/A", "69.8", "54.7", "85.8", "54.3", "75.5", …
$ fiscal_health <chr> "N/A", "51.7", "13.8", "91.1", "35.7", "69.1", …
$ business_freedom <chr> "N/A", "74.1", "54.4", "44.6", "55.5", "69.2", …
$ labor_freedom <chr> "N/A", "51.5", "51.4", "50.8", "53.5", "58.9", …
$ monetary_freedom <chr> "N/A", "75.7", "71.9", "60", "29.4", "67.5", "7…
$ trade_freedom <chr> "N/A", "82.6", "57.4", "68.6", "58.6", "73.6", …
$ investment_freedom <chr> "N/A", "70", "30", "30", "55", "75", "80", "80"…
$ financial_freedom <chr> "N/A", "70", "30", "40", "60", "70", "90", "70"…library(readxl)
corrupcion <- read_excel("CPI2024-Results-and-trends.xlsx", range = "A3:V183", sheet = "CPI 2024") %>%
clean_names()
glimpse(corrupcion)Rows: 180
Columns: 22
$ country_territory <chr> "Denmark", "Finlan…
$ iso3 <chr> "DNK", "FIN", "SGP…
$ region <chr> "WE/EU", "WE/EU", …
$ cpi_2024_score <dbl> 90, 88, 84, 83, 81…
$ rank <dbl> 1, 2, 3, 4, 5, 5, …
$ standard_error_2024 <dbl> 1.982749, 1.829536…
$ number_of_sources <dbl> 8, 8, 9, 8, 7, 8, …
$ lower_ci <dbl> 86.74829, 84.99957…
$ upper_ci <dbl> 93.25171, 91.00043…
$ african_development_bank_cpia <dbl> NA, NA, NA, NA, NA…
$ bertelsmann_foundation_sustainable_governance_index <dbl> 97, 97, NA, 87, NA…
$ bertelsmann_foundation_transformation_index <dbl> NA, NA, 77, NA, NA…
$ economist_intelligence_unit_country_ratings <dbl> 83, 83, 83, 83, 83…
$ freedom_house_nations_in_transit <dbl> NA, NA, NA, NA, NA…
$ s_p_global_insights_country_risk_ratings <dbl> 85, 85, 85, 85, 72…
$ imd_world_competitiveness_yearbook <dbl> 97, 93, 82, 87, 77…
$ perc_asia_risk_guide <dbl> NA, NA, 89, NA, NA…
$ prs_international_country_risk_guide <dbl> 100, 96, 78, 96, 8…
$ varieties_of_democracy_project <dbl> 75, 74, 74, 74, 73…
$ world_bank_cpia <dbl> NA, NA, NA, NA, NA…
$ world_economic_forum_eos <dbl> 95, 92, 100, 72, 9…
$ world_justice_project_rule_of_law_index <dbl> 87, 84, 84, 83, 79…Ahora procedo a estimar los coeficientes del modelo \[ \text{Libertad (overall score)}_p = \beta_0 + \beta_1 \text{Corrupción (CPI score)}_p + \varepsilon \]
El modelo corresponde a un modelo de corte transversal donde “p” denota país y todas las observaciones son del año 2024. La variable dependiente es la puntuación general de libertad económica y la variable independiente es la puntuación de percepción de corrupción.
datos_modelo <- corrupcion %>%
select(country_territory, cpi_2024_score) %>%
left_join(libertad %>% select(country, overall_score), by = c("country_territory" = "country"))
# casos sin match
datos_modelo %>%
filter(is.na(overall_score)) %>%
pull(country_territory) %>%
sort() [1] "Bahamas" "Congo"
[3] "Czechia" "Democratic Republic of the Congo"
[5] "Gambia" "Grenada"
[7] "Hong Kong" "Korea, North"
[9] "Korea, South" "Kyrgyzstan"
[11] "Myanmar" "Philippines"
[13] "Sao Tome and Principe" "South Sudan"
[15] "Turkey" # busco en libertad los paises sin match
libertad %>%
select(country) %>%
left_join(corrupcion %>% select(country_territory, cpi_2024_score), by = c("country" = "country_territory")) %>%
filter(is.na(cpi_2024_score)) %>%
pull(country) %>%
sort() [1] "Belize" "Brunei Darussalam"
[3] "Burma" "Czech Republic"
[5] "Democratic Republic of Congo" "Kiribati"
[7] "Kyrgyz Republic" "Liechtenstein"
[9] "Micronesia" "North Korea"
[11] "Republic of Congo" "Samoa"
[13] "São Tomé and Príncipe" "South Korea"
[15] "The Bahamas" "The Gambia"
[17] "The Philippines" "Tonga"
[19] "Türkiye" # casos con match que debo arreglar:
# corrupcion - libertad
# Congo - Republic of Congo
# Czechia - Czech Republic
# Democratic Republic of the Congo - Democratic Republic of Congo
# Korea, North - North Korea
# Korea, South - South Korea
# Kyrgyzstan - Kyrgyz Republic
# Philippines - The Philippines
# Sao Tome and Principe - São Tomé and Príncipe
# Turkey - Türkiye
datos_modelo <- corrupcion %>%
mutate(
country_territory = case_when(
country_territory == "Congo" ~ "Republic of Congo",
country_territory == "Czechia" ~ "Czech Republic",
country_territory == "Democratic Republic of the Congo" ~ "Democratic Republic of Congo",
country_territory == "Korea, North" ~ "North Korea",
country_territory == "Korea, South" ~ "South Korea",
country_territory == "Kyrgyzstan" ~ "Kyrgyz Republic",
country_territory == "Philippines" ~ "The Philippines",
country_territory == "Sao Tome and Principe" ~ "São Tomé and Príncipe",
country_territory == "Turkey" ~ "Türkiye",
TRUE ~ country_territory
)
) %>%
select(country_territory, cpi_2024_score) %>%
left_join(libertad %>% select(country, overall_score), by = c("country_territory" = "country")) %>%
mutate(overall_score = as.numeric(overall_score))
# verifico que los casos sin match que quedan sean los que no tienen datos en libertad
datos_modelo %>%
filter(is.na(overall_score))# A tibble: 13 × 3
country_territory cpi_2024_score overall_score
<chr> <dbl> <dbl>
1 Hong Kong 74 NA
2 Bahamas 65 NA
3 Grenada 56 NA
4 Gambia 38 NA
5 Ukraine 35 NA
6 Iraq 26 NA
7 Afghanistan 17 NA
8 Myanmar 16 NA
9 Libya 13 NA
10 Yemen 13 NA
11 Syria 12 NA
12 Somalia 9 NA
13 South Sudan 8 NAAhora estimo los coeficientes del modelo de regresión lineal:
mod1 <- lm(overall_score ~ cpi_2024_score, data = datos_modelo)
summary(mod1)
Call:
lm(formula = overall_score ~ cpi_2024_score, data = datos_modelo)
Residuals:
Min 1Q Median 3Q Max
-42.275 -3.485 0.865 4.588 13.141
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 38.13669 1.41629 26.93 <2e-16 ***
cpi_2024_score 0.46919 0.02981 15.74 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.183 on 165 degrees of freedom
(13 observations deleted due to missingness)
Multiple R-squared: 0.6002, Adjusted R-squared: 0.5977
F-statistic: 247.7 on 1 and 165 DF, p-value: < 2.2e-16De acuerdo a estos coeficientes, la pendiente estimada es positiva, lo que indica que a medida que aumenta la puntuación de percepción de corrupción (lo que indica menor corrupción), también aumenta la puntuación de libertad económica.
¿Qué ocurre si elimino los puntos palanca? Mediante la distancia de Cook, cuya fórmula es: \[
D_i = \frac{e_i^2}{p \cdot \text{MSE}} \times \frac{h_{ii}}{(1 - h_{ii})^2}
\] donde \(e_i\) es el residuo del punto \(i\), \(p\) es el número de parámetros en el modelo, \(MSE\) es el error cuadrático medio del modelo, y \(h_{ii}\) es la diagonal de la matriz de proyección para el punto \(i\). Esto se puede calcular fácilmente con la función augment() del paquete broom:
# identifico puntos palanca con distancia de Cook
library(ggplot2)
library(broom)
datos_modelo_aug <- augment(mod1)
ggplot(datos_modelo_aug, aes(x = cpi_2024_score, y = overall_score)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE, color = "blue") +
# distancia > 4 = rojo
geom_point(data = datos_modelo_aug %>% filter(.cooksd > 4 / nrow(datos_modelo_aug)), color = "red", size = 5,
shape = 17) +
labs(title = "Distancia de Cook para identificar puntos palanca",
x = "Puntuación de percepción de corrupción (CPI 2024)",
y = "Puntuación de libertad económica (Overall Score)") +
theme_minimal()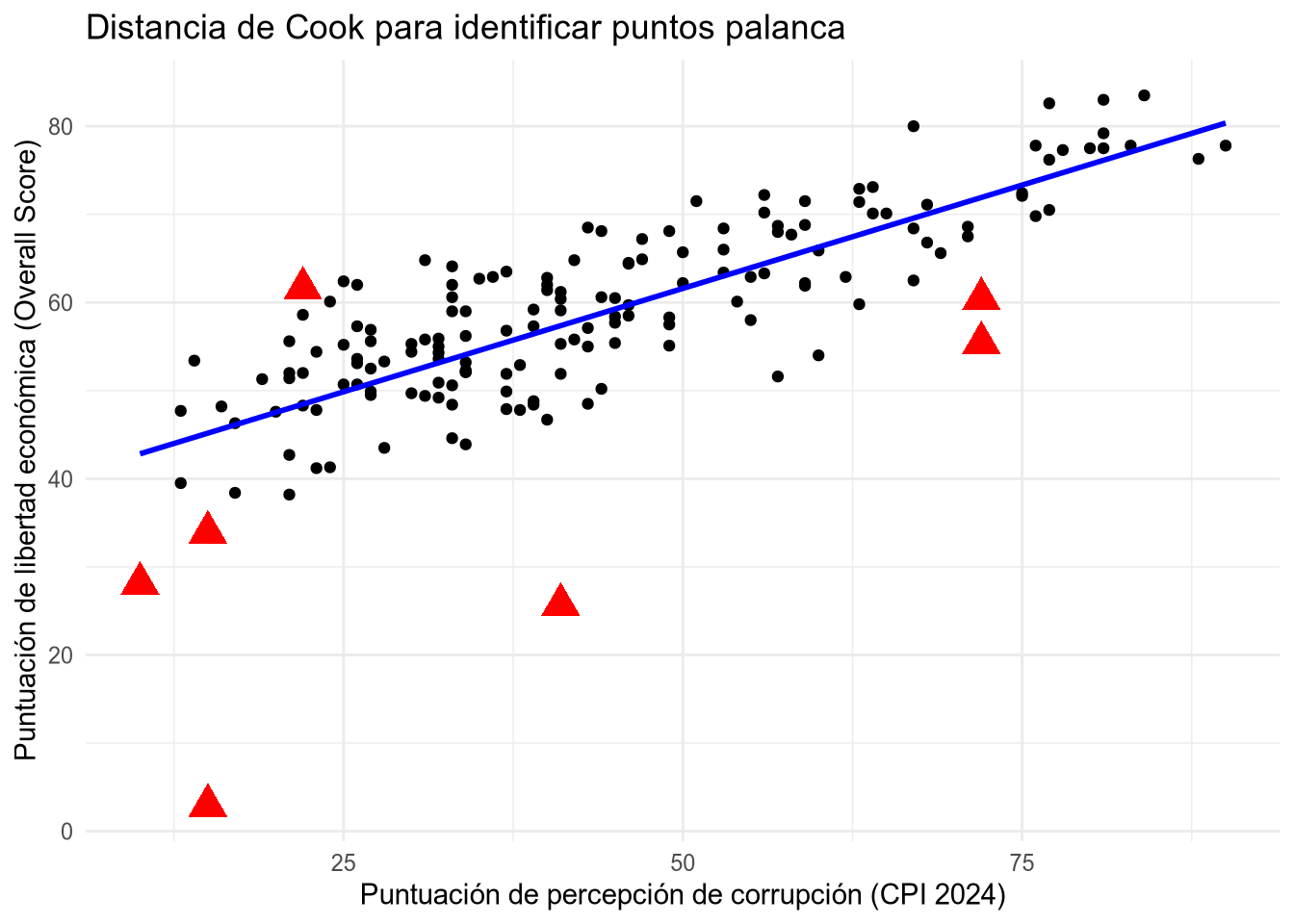
# elimino puntos palanca
datos_modelo_sin_palanca <- datos_modelo_aug %>%
filter(.cooksd <= 4 / nrow(datos_modelo_aug))
mod1_sin_palanca <- lm(overall_score ~ cpi_2024_score, data = datos_modelo_sin_palanca)
summary(mod1_sin_palanca)
Call:
lm(formula = overall_score ~ cpi_2024_score, data = datos_modelo_sin_palanca)
Residuals:
Min 1Q Median 3Q Max
-13.7350 -3.8310 0.5907 3.9498 11.4279
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 39.75105 1.12745 35.26 <2e-16 ***
cpi_2024_score 0.44884 0.02364 18.98 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.452 on 158 degrees of freedom
Multiple R-squared: 0.6952, Adjusted R-squared: 0.6933
F-statistic: 360.4 on 1 and 158 DF, p-value: < 2.2e-16Al eliminar los puntos palanca, la pendiente estimada del modelo disminuye, pero sigue siendo positiva. El cambio es de 4.4% aproximadamente:
cf <- coef(mod1_sin_palanca)[2]
ci <- coef(mod1)[2]
(cf - ci) / ci * 100cpi_2024_score
-4.336817 Ya que la pendiente que obtengo es la inversa del post original, no experimentaré con otras formas funcionales. Lo que se ve en mi gráfico puede tener una o más de las siguientes explicaciones:
En conclusión, el análisis presentado en el post de David Hernández requiere de una revisión que debe hacerse con cautela, especialmente cuando se trata de fenómenos sociales como la corrupción y sus nefastas consecuencias económicas. Esto se debe hacer sin burlas, descalificaciones o comentarios groseros, sino con un análisis riguroso y fundamentado. Me gustaría leer el código de David Hernández para entender mejor cómo llegó a sus conclusiones y a una pendiente negativa.