The tesseract package provides R bindings Tesseract: a powerful optical character recognition (OCR) engine that supports over 100 languages. The engine is highly configurable in order to tune the detection algorithms and obtain the best possible results.
Keep in mind that OCR (pattern recognition in general) is a very difficult problem for computers. Results will rarely be perfect and the accuracy rapidly decreases with the quality of the input image. But if you can get your input images to reasonable quality, Tesseract can often help to extract most of the text from the image.
Extract Text from Images
OCR is the process of finding and recognizing text inside images, for example from a screenshot, scanned paper. The image below has some example text:

Image with eight lines of English text
The ocr() function extracts text from an image file. After indicating the engine for the language, it will return the text found in the image:
library(cpp11tesseract)
file <- system.file("examples", "wilde.png", package = "cpp11tesseract")
eng <- tesseract("eng")
text <- ocr(file, engine = eng)
cat(text)Complete Works
oF
OSCAR WILDE
EDITED BY
ROBERT ROSS
MISCELLANIES
‘AUTHORIZED EDITION
THE WYMAN-FOGG COMPANY
BOSTON :: MASSACHUSETTSThe ocr_data() function returns all words in the image along with a bounding box and confidence rate.
results <- ocr_data(file, engine = eng)
results# A tibble: 18 × 4
word confidence bbox stringsAsFactors
<chr> <dbl> <chr> <lgl>
1 Complete 96.5 159,48,304,79 FALSE
2 Works 96.5 320,49,422,74 FALSE
3 oF 66.3 281,102,300,111 FALSE
4 OSCAR 94.9 92,131,274,161 FALSE
5 WILDE 96.6 308,132,490,167 FALSE
6 EDITED 95.2 248,187,303,197 FALSE
7 BY 96.6 314,187,334,197 FALSE
8 ROBERT 96.1 207,212,302,227 FALSE
9 ROSS 96.1 318,212,373,227 FALSE
10 MISCELLANIES 90.8 195,298,389,316 FALSE
11 ‘AUTHORIZED 82.2 200,504,306,515 FALSE
12 EDITION 96.8 315,503,382,514 FALSE
13 THE 93.2 144,664,184,677 FALSE
14 WYMAN-FOGG 90.3 195,663,331,676 FALSE
15 COMPANY 95.8 342,662,438,675 FALSE
16 BOSTON 66.6 144,693,218,706 FALSE
17 :: 81.4 246,697,255,705 FALSE
18 MASSACHUSETTS 90.9 279,691,438,704 FALSELanguage Data
The tesseract OCR engine uses language-specific training data in the recognize words. The OCR algorithms bias towards words and sentences that frequently appear together in a given language, just like the human brain does. Therefore the most accurate results will be obtained when using training data in the correct language.
Use tesseract_info() to list the languages that you currently have installed.
$datapath
[1] "/usr/share/tesseract-ocr/5/tessdata/"
$available
[1] "chi_sim" "eng" "osd"
$version
[1] "5.4.1"
$configs
[1] "alto" "ambigs.train" "api_config" "bigram"
[5] "box.train" "box.train.stderr" "digits" "get.images"
[9] "hocr" "inter" "kannada" "linebox"
[13] "logfile" "lstm.train" "lstmbox" "lstmdebug"
[17] "makebox" "page" "pdf" "quiet"
[21] "rebox" "strokewidth" "tsv" "txt"
[25] "unlv" "wordstrbox"By default the R package only includes English training data. Windows and Mac users can install additional training data using tesseract_download(). Let’s OCR a screenshot from Wikipedia in Simplified Chinese.

Image with thirteen lines of Chinese text
# Download once
dir <- tempdir()
tesseract_download("chi_sim", model = "fast", datapath = dir) Downloaded: 2.35 MB (100%)
[1] "/tmp/RtmpfeKjPP/chi_sim.traineddata"
# Load the dictionary
file <- system.file("examples", "chinese.jpg", package = "cpp11tesseract")
text <- ocr(file, engine = tesseract("chi_sim", datapath = dir))
cat(text)奥林匹克运动会 (希腊语;: OMXohrtakot AYWvsc; 法语: Jeux olympiques; 英语:
Olympic Games) ,简称奥运会、奥运,是世界最高等级的国际综合体育蹇事,由国际
奥林匹克委员会主办,每4年举行一次。冬季训技项目创立冬季奥林匹克运动会后,之前
的奥林匹克运动会则是又称为【夏季奥林匹克还动会」 以示区分。从1994年起,冬季奥
还会和夏季奥运会分并,相隔2年交蔡举行。奥林匹克运动会最早起源於古希腊,是当时
各城邦之间的公开较量,因为皋闪地在奥林匹亚而得名。信幸基晴教的办天皇帝狄奥多西
一世以奥林匹克运动会崇拜耶稣以外神只为由,禁止奥运项技,於是奥运在举办超过
1,000年后於4世纪末停办,奥运这次停办持续了1,503年,直到19世纪未才由和后人发现
遗距。之后,法辆的顾拜旦男超皮耶,德:古柏坦创立了有真正奥运精神的现代奥林匹克运
动会,自1896年开始每4年学办一次,更确立了会期不超过18日的传统。现代奥运会只
在两次世界大战期间合共中断过5次(分别是191 6年夏季奥运会、1940年夏季奥运会
D、1940年冬季奥运会(1]、1944年夏季奥运会和1944年冬季奥运会) [广 ]],以及在
2020年因全球防疫延期过一次 (2020年夏季奥运会2][广习) 。Compare with the copy and paste from the Wikipedia.
text2 <- readLines(system.file("examples", "chinese.txt",
package = "cpp11tesseract"))
cat(text2)奧林匹克運動會(希臘語:Ολυμπιακοί Αγώνες;法語 Jeux olympiques;英語:Olympic Games簡
稱奧運會、奧運,是世界最高等級的國際綜合體育賽事,由國際 奧林匹克委員會主辦,每4年舉行一次。冬
季競技項目創立冬季奧林匹克運動會後,之前 的奧林匹克運動會則是又稱為「夏季奧林匹克運動會」以示區
分。從1994年起,冬季奧 運會和夏季奧運會分開,相隔2年交替舉行。奥林匹克運動會最早起源於古希腊,
是當時 各城邦之間的公開較量,因為舉辦地在奧林匹亚而得名。信奉基督教的羅馬皇帝狄奧多西 一世以奧
林匹克運動會崇拜耶穌以外神衹為由,禁止奧運競技,於是奧運在舉辦超過 1,000年後於4世紀末停辦,奧
運這次停辦持續了1,503年,直到19世纪末才由後人發現 遺蹟。之後,法國的顾拜旦男爵皮耶·德·古柏坦
創立了有真正奧運精神的現代奧林匹克運 動會,自1896年開始每4年舉辦一次,更確立了會期不超過18日
的傳統。現代奧運會只 在兩次世界大戰期間合共中斷過5次(分別是1916年夏季奧運會、1940年夏季奧運
會 [1]、1940年冬季奧運會[1]、1944年夏季奧運會和1944年冬季奧運會)[註 1],以及在 2020年因
全球防疫延期過一次(2020年夏季奧運會[2][註 2])。Read from PDF files
If your images are stored in PDF files they first need to be converted to a proper image format. We can do this in R using the pdf_convert function from the cpp11poppler package. Use a high DPI to keep quality of the image.
library(cpp11poppler)
file <- system.file("examples", "bondargentina.pdf", package = "cpp11tesseract")
pngfile <- pdf_convert(file, dpi = 600)
text <- ocr(pngfile)
cat(text)_ LISTING PARTICULARS CONSISTING OF
Pricing Supplement, Supplemental Information Memorandum and
Supplemental Information Memorandum Addendum dated May 26, 1998
AND
Information Memorandum Addendum dated October 17, 1997 |
ee .
THE REPUBLIC OF ARGENTINA
Euro 750,000,000 Interest Strip Notes due 2028
issued under its
U.S.$11,000,000,000
EURO MEDIUM-TERM NOTE PROGRAMME |
Issue Price: 100.835 per cent.
Series No.: 61
Tranche No.: 01 :
Dealer
ABN AMRO
The date of these Listing Particulars is May 26, 1998.
The Republic has warranted to the Dealer that, inter alia, these Listing
Particulars are true and accurate in all material respects, do not contain any
untrue statement of material fact nor omit to state any material fact known to
the Republic necessary to make statements herein not misleading and all
reasonable enquiries have been made to ascertain such facts and to verify the
accuracy of all such statements. The Republic accepts responsibility
accordingly.
No person has been authorised to give any information or to make any
representations, other than those contained in the Listing Particulars, in
connection with the offering or sale of the Notes and, if given or made, such
information or representations must not be relied upon as having been authorised
by the Republic or the Dealer. Neither the delivery of these Listing Particulars
nor any sale made hereunder shall, under any circumstances, constitute a
representation that there has been no change in the financial position or
prospects of the Republic since the date hereof or the information contained
herein is correct as of any time subsequent to the date hereof.Tesseract Control Parameters
Tesseract supports hundreds of “control parameters” which alter the OCR engine Use tesseract_params() to list all parameters with their default value and a brief description. It also has a handy filter argument to quickly find parameters that match a particular string.
# List all parameters with *colour* in name or description
tesseract_params("colour")# A tibble: 2 × 3
param default desc
* <chr> <chr> <chr>
1 editor_image_word_bb_color 7 Word bounding box colour
2 editor_image_blob_bb_color 4 Blob bounding box colourDo note that some of the control parameters have changed between Tesseract engine 3 and 4.
tesseract_info()["version"][1] "5.4.1"Whitelist / Blacklist characters
One powerful parameter is tessedit_char_whitelist which restricts the output to a limited set of characters. This may be useful for reading for example numbers such as a bank account, zip code, or gas meter.
The whitelist parameter works for all versions of Tesseract engine 3 and also engine versions 4.1 and higher, but unfortunately it did not work in Tesseract 4.0.

A receipt in English with food and toys for Mr. Duke
file <- system.file("examples", "receipt.jpg", package = "cpp11tesseract")
numbers <- tesseract(options = list(tessedit_char_whitelist = "-$.0123456789"))
cat(ocr(file, engine = numbers))0
00068354712539
01.8$31.998
25 -$8.00
00084019961505
03966$44.99
00003558543582
8 $8.93
$
00000002000414
$0.50
$$60$10 -$10.00
$ $68.47
$8.84
$77.31To test if this actually works, look at the output without the whitelist:
DOG
000683547 12539
OPEN FARM DOG AG SALMON 1.8KG $31.99 HST
Item discount 25% -$8.00 HST
00084019961505
VE FO GOOG BF NIB 396G LRG KONG $44.99 HST
ACCESSORIES
00003558543582
KONG BRUSH $8.93 HST
STORE USE ITEMS
000000020004 14
GPF CLOTH BAG LARGE $0.50
FPS SPEND $60 SAVE $10 -$10.00
SUB TOTAL $68.47
HST $8.84
TOTAL $77.31This is Mr. Duke:

Mr. Duke, a dog of the Australian Sheppard kind
Here is the extracted text:
file <- system.file("examples", "mrduke.jpg", package = "cpp11tesseract")
text <- ocr(file, engine = eng)
cat(text)ee
oe e
Ze. <n BR ee
Mr. Duke, 4 years old (2024) 2Best versus Fast models
In order to improve the OCR results, Tesseract has two variants of models that can be used. The tesseract_download() can download the ‘best’ (but slower) model, which increases the accuracy. The ‘fast’ (but less accurate) model is the default.
Compare the result with the previous example with Chinese text:
file <- system.file("examples", "chinese.jpg", package = "cpp11tesseract")
# download the best model (vertical script download is to avoid a warning)
dir <- tempdir()
tesseract_download("chi_sim_vert", model = "best", datapath = dir)
tesseract_download("chi_sim", model = "best", datapath = dir)
text <- ocr(file, engine = tesseract("chi_sim", datapath = dir))
# compare the results: fast (text1) vs best (text2)
cat(text)奥林匹克运动会 (希腊语;: OMXohrtakot AYWvsc; 法语: Jeux olympiques; 英语:
Olympic Games) ,简称奥运会、奥运,是世界最高等级的国际综合体育蹇事,由国际
奥林匹克委员会主办,每4年举行一次。冬季训技项目创立冬季奥林匹克运动会后,之前
的奥林匹克运动会则是又称为【夏季奥林匹克还动会」 以示区分。从1994年起,冬季奥
还会和夏季奥运会分并,相隔2年交蔡举行。奥林匹克运动会最早起源於古希腊,是当时
各城邦之间的公开较量,因为皋闪地在奥林匹亚而得名。信幸基晴教的办天皇帝狄奥多西
一世以奥林匹克运动会崇拜耶稣以外神只为由,禁止奥运项技,於是奥运在举办超过
1,000年后於4世纪末停办,奥运这次停办持续了1,503年,直到19世纪未才由和后人发现
遗距。之后,法辆的顾拜旦男超皮耶,德:古柏坦创立了有真正奥运精神的现代奥林匹克运
动会,自1896年开始每4年学办一次,更确立了会期不超过18日的传统。现代奥运会只
在两次世界大战期间合共中断过5次(分别是191 6年夏季奥运会、1940年夏季奥运会
D、1940年冬季奥运会(1]、1944年夏季奥运会和1944年冬季奥运会) [广 ]],以及在
2020年因全球防疫延期过一次 (2020年夏季奥运会2][广习) 。Contributed models
The tesseract_contributed_download() function can download contributed models. For example, the grc_hist model is useful for Polytonic Greek. Here is an example from Sophocles’ Ajax (source: Ajax Multi-Commentary)

polytonicgreek
file <- system.file("examples", "polytonicgreek.png", package = "cpp11tesseract")
# download the best models
dir <- tempdir()
tesseract_download("grc", datapath = dir, model = "best")
tesseract_contributed_download("grc_hist", datapath = dir, model = "best")
# compare the results: grc (text1) vs grc_hist (text2)
text1 <- ocr(file, engine = tesseract("grc", datapath = dir))
text2 <- ocr(file, engine = tesseract("grc_hist", datapath = dir))
cat(text1)
cat(text2)232» Α 2 [ 2 Α Ὕ ’, ᾿»
ἠὲ καὶ ἀμφαδίην, ἐπεὶ οὐ τινά δείδιμεν ἔμπης"
οὐ γάρ τίς μὲ βίῃ γε ἑκὼν ἀέχοντα δίηται,
2 ᾿ 2 ’ 2 " 2 2 2 Α ».. ΄ 2 Ὁ“
οὐδέ τε ἰδρείῃ, ἐπεὶ οὐδ΄ ἐμὲ νήϊδά γ᾽ οὕτως
ἔλπομαι ἐν Σαλαμῖνι γενέσϑαι τε τραφέμεν τε.20 Ε 2 Σ. ΣΣ ν
ἠὲ καὶ ἀμφαδίην, ἐπεὶ οὔ τινα δείδιμεν ἔμπης·
οὐ γάρ τίς με βίῃ γε ἑκὼν ἀέκοντα δίηται,
2 . 2 ’ 2 ο 2 2 Σ Α ΣΣΣ . 2 ῳ.
οὐδέ τι ἰδρείῃ, ἐπεὶ οὐδ’ ἐμὲ νήϊδά γ’ οὕτως
ἔλπομαι ἐν Σαλαμῖνι γενέσθαι τε τραφέμεν τε.Comparison with Amazon Textract
Note: Amazon and Textract are trademarks of Amazon.com, Inc.
Textract documentation uses page three of the January 1966 report from Philadelphia Fed’s Tealbook (formerly Greenbook).
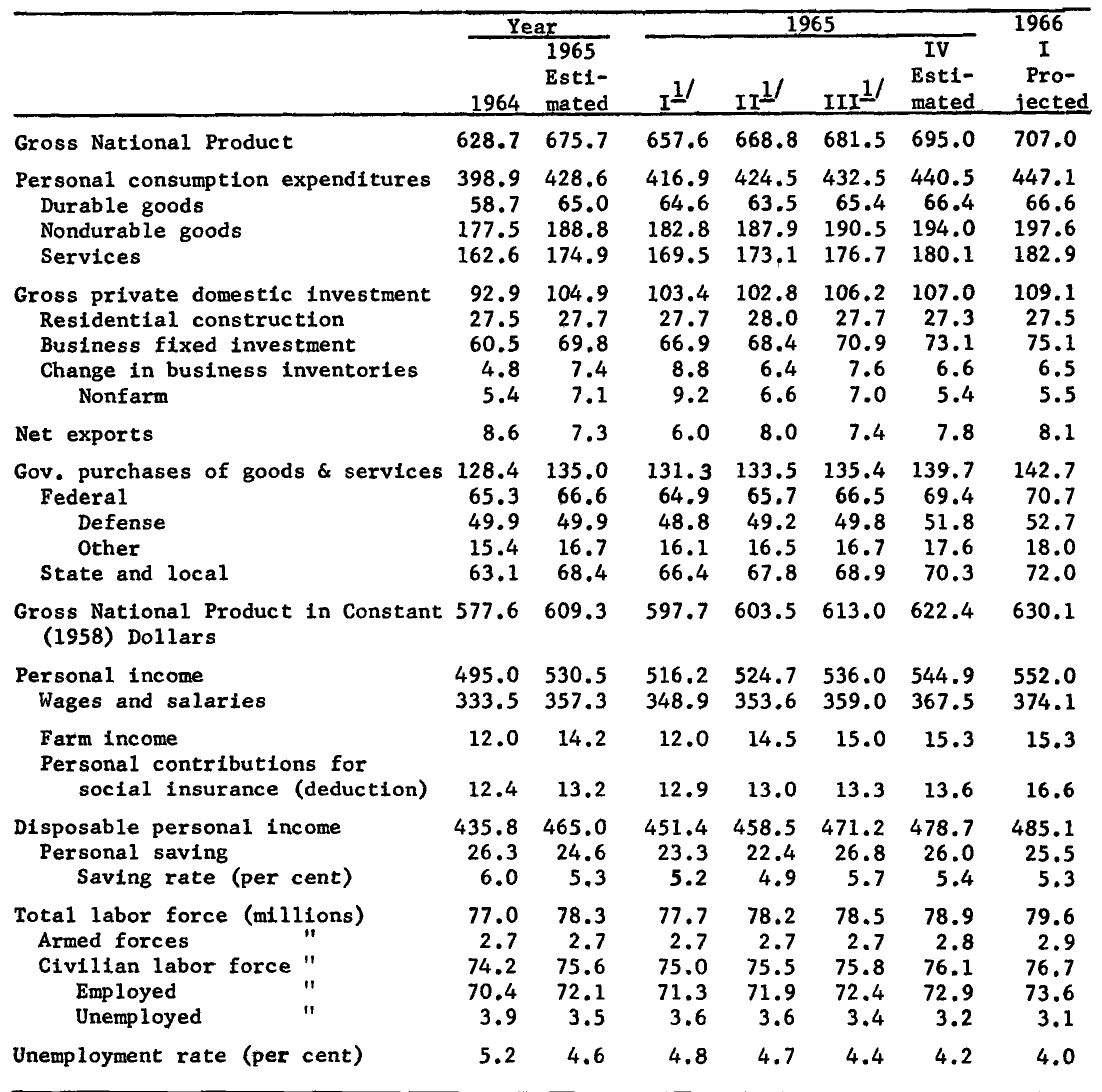
tealbook
Here is the first element of the list returned by Textract:
# List of 13
# $ BlockType : chr "TABLE"
# $ Confidence : num 100
# $ Text : chr(0)
# $ RowIndex : int(0)
# $ ColumnIndex : int(0)
# $ RowSpan : int(0)
# $ ColumnSpan : int(0)
# $ Geometry :List of 2
# .. <not shown>
# $ Id : chr "c6841638-d3e0-414b-af12-b94ed34aac8a"
# $ Relationships :List of 1
# ..$ :List of 2
# .. ..$ Type: chr "CHILD"
# .. ..$ Ids : chr [1:256] "e1866e80-0ef0-4bdd-a6fd-9508bb833c03" ...
# $ EntityTypes : list()
# $ SelectionStatus: chr(0)
# $ Page : int 3Here is Tesseract’s output:
file <- system.file("examples", "tealbook.png", package = "cpp11tesseract")
text <- ocr(file)
cat(text)Nemes mm a a ee en e-em n an ae ee
Year SSC—~SSESSC~*«C
1965 IV I
Esti- Esti- Pro-
1964 __mated yi/ rr/ rrr! mated _ jected
Gross National Product 628.7 675.7 657.6 668.8 681.5 695.0 707.0
Personal consumption expenditures 398.9 428.6 416.9 424.5 432.5 440.5 447.1
Durable goods 58.7 65.0 64.6 63.5 65.4 66.4 66.6
Nondurable goods 177.5 188.8 182.8 187.9 190.5 194.0 197.6
Services 162.6 174.9 169.5 173,1 176.7 180.1 182.9
Gross private domestic investment 92.9 104.9 103.4 102.8 106.2 107.0 109.1
Residential construction 27.5 27.7 27.7 28.0 27.7 27.3 27.5
Business fixed investment 60.5 69.8 66.9 68.4 70.9 73.1 75.1
Change in business inventories 4.8 7.4 8.8 6.4 7.6 6.6 6.5
Nonfarm 5.4 7.1 9.2 6.6 7.0 5.4 5.5
Net exports 8.6 7.3 6.0 8.0 7.4 7.8 8.1
Gov. purchases of goods & services 128.4 135,0 131.3 133.5 135.4 139.7 142.7
Federal 65.3 66.6 64.9 65.7 66.5 69.4 70.7
Defense 49.9 49.9 48.8 49.2 49.8 51.8 52.7
Other 15.4 16.7 16.1 16.5 16.7 17.6 18.0
State and local 63.1 68,4 66.4 67.8 68.9 70.3 72.0
Gross National Product in Constant 577.6 609.3 597.7 603.5 613.0 622.4 630.1
(1958) Dollars
Personal income 495.0 530.5 516.2 524.7 536.0 544.9 552.0
Wages and salaries 333.5 357.3 348.9 353.6 359.0 367.5 374.1
Farm income 12.0 14.2 12.0 14.5 15.0 15.3 15.3
Personal contributions for
social insurance (deduction) 12.4 13.2 12.9 13.0 13.3 13.6 16.6
Disposable personal income 435.8 465.0 451.4 458.5 471.2 478.7 485.1
Personal saving 26.3 24.6 23.3 22.4 26.8 26.0 25.5
Saving rate (per cent) 6.0 5.3 5.2 4.9 5.7 5.4 5.3
Total labor force (millions) 77.0 78.3 77.7. 78.2 78.5 78.9 79.6
Armed forces " 2.7 2.7 2.7 2.7 2.7 2.8 2.9
Civilian labor force " 74.2 75.6 75.0 75.5 75.8 76,1 76,7
Employed " 70.4 72.1 71.3 71.9 72.4 72.9 73.6
Unemployed " 3.9 3.5 3.6 3.6 3.4 3.2 3.1
Unemployment rate (per cent) 5.2 4.6 4.8 4.7 4.4 4.2 4.0One way to organize the output is to split the text before the first digit on each line.
text <- strsplit(text, "\n")[[1]]
text <- text[6:length(text)]
for (i in seq_along(text)) {
firstdigit <- regexpr("[0-9]", text[i])[1]
variable <- trimws(substr(text[i], 1, firstdigit - 1))
values <- strsplit(substr(text[i], firstdigit, nchar(text[i])), " ")[[1]]
values <- trimws(gsub(",", ".", values))
values <- suppressWarnings(as.numeric(gsub("\\.$", "", values)))
if (length(values[!is.na(values)]) < 1) {
next
}
res <- c(variable, values)
names(res) <- c(
"variable", "y1964", "y1965est", "y1965q1",
"y1965q2", "y1965q3", "y1965q4est", "y1966q1pro"
)
if (i == 1) {
df <- as.data.frame(t(res))
} else {
df <- rbind(df, as.data.frame(t(res)))
}
}
head(df) variable y1964 y1965est y1965q1 y1965q2 y1965q3
1 Gross National Product 628.7 675.7 657.6 668.8 681.5
2 Personal consumption expenditures 398.9 428.6 416.9 424.5 432.5
3 Durable goods 58.7 65 64.6 63.5 65.4
4 Nondurable goods 177.5 188.8 182.8 187.9 190.5
5 Services 162.6 174.9 169.5 173.1 176.7
6 Gross private domestic investment 92.9 104.9 103.4 102.8 106.2
y1965q4est y1966q1pro
1 695 707
2 440.5 447.1
3 66.4 66.6
4 194 197.6
5 180.1 182.9
6 107 109.1The result is not perfect (e.g. I still need to change “Gross National Product in Constant” to add the “(1958) Dollars”), but neither is Textract’s and it requires to write a more complex loop to organize the data. Certainly, this can be simplified by using the Tidyverse.